
Blog
November 9, 2022
Ein konsistentes Produktdatenmodell ist fundamental für den Verkaufserfolg. Denn nur ein umfangreiches a Produktdatenmodell bietet den Kunden die gewünschten Filter, um das gewünschte Produkt schnell zu finden und die Möglichkeit verschiedene Wunschartikel zu vergleichen.
Dies stellt Händler vor die grosse Herausforderung umfangreichere Produktdatenmodelle auf dem für das Unternehmen geeigneten PIM-System abzubilden. Produktdatenmodelle geben vor, wie Produkte am besten durch welche Attribute beschrieben werden, enthalten für konsistente Suchfilter alle benötigten Wertelisten und erleichtern das Setup einer umfassenden Produktdaten-Governance, enthalten also den Kategorienbaum. Zudem indiziert das Modell welche Informationen Lieferanten zu den Produkten und Artikeln bereitstellen sollen. Dank Continuous Migration können neue Produktdatenmodelle schnell, praxisnah, agil und vor allem iterativ geprüft und allenfalls angepasst werden. Wie das funktioniert und weshalb dieser Ansatz so wichtig ist, wird im Folgenden erklärt.
Wann braucht es den Continuous Migration Ansatz?
Im Wesentlichen gibt es zwei Use Cases, welche das schnelle Überprüfen eines neuen Datenmodells notwendig machen. Zum einen, wenn das gesamte bestehende Produktdatenmodell neu gedacht werden muss, weil bisherige Strukturen nicht mehr ausreichen oder wenn ein PIM-System neu eingeführt wird.
PIM-Systeme sind aus mehreren Gründen nicht mehr aus der modernen Welt wegzudenken: Zum einen dient das PIM als zentrale Datenbank für alle produktbezogenen Informationen und zum anderen erleichtert es die weitere Verarbeitung dieser Daten zum Beispiel für Webshops oder Kataloge. Damit alle Möglichkeiten des PIM-Systems ausgeschöpft werden können, muss ein entsprechendes Produktdatenmodell im PIM hinterlegt werden. Doch wie baut man ein solches korrekt auf?
Das Erstellen eines Produktdatenmodells erfolgt in zwei Phasen. In einem ersten Schritt werden Kategorien verfeinert oder neu erstellt und damit der Kategorienbaum erstellt beziehungsweise überarbeitet. Danach müssen pro Kategorie beziehungsweise Produktfamilie mit einem einheitlichen Attribut-Set beschrieben werden. Zum Abschluss müssen die Metadaten (Datentypen, Wertelisten, Einheiten, etc.) pro Attribut festgelegt werden.
Wie funktioniert die kontinuierliche Migration?
Eine grosse Hürde bei der Einführung eines neuen Produktdatenmodells ist, dieses auf seine Vollständigkeit hin zu prüfen und zu testen ob es mit den bereits vorhandenen Produktdaten gut abgebildet werden kann. Die Plausibilisierung des neuen Produktdatenmodells wird im klassischen Ansatz mittels einer Vollmigration und danach folgend eine bis zwei Iterationen vollzogen. Dies ist aus mehrerlei Hinsicht schwerfällig: Alles muss auf Papier und weit weg von den eigentlichen Produktdaten überlegt und mit langer Vorlaufzeit theoretisch erörtert, beschrieben und möglichst vollendet eingeführt werden. Dies ist mit grossen personellen Aufwänden und gebundenen Rescourcen verbunden. Zudem ist das Anpassen und Nachschärfen des Produktdatenmodells zeitintensiv, aufwändig und umfassend.
Continuous Migration beziehungsweise der Ansatz 2.0 hebelt die Schwerfälligkeit des klassischen IT-Migrationsansatzes gekonnt aus: Anstelle von einer grossen und schwerfälligen Migration, wird auf viele kleine Iterationen gesetzt. Dadurch, dass schnell Feedback erhalten wird, können Anpassungen punktuell gemacht und überprüft werden. Dadurch wird die Produktdatenmodellqualität schnell, agil und iterativ Iteration für Iteration erheblich erhöht. Denn nur wer schnell mit den vorhandenen Daten und deren Mappings arbeiten kann, sieht auch schnell wo Verbesserungen notwendig sind.
Die Umsetzung sieht in der Praxis wie folgt aus: Das neue Datenmodell wird auf die Onedot Produktdatenplattform und gewünschten PIM-Testsystem angelegt. Die bestehenden Produktdaten aus dem Live-System werden ebenso in die Produktdatenplattform geladen. Mit diesen Angaben kann die KI-gestütze Software von Onedot bestehende Produktdaten auf das neue Modell mappen. Dabei werden die Produktinformationen in einem klar gegliederten Prozess auf die vom Produktdatenmodell vorgegbenen Strukturen hin automatisiert abgebildet.
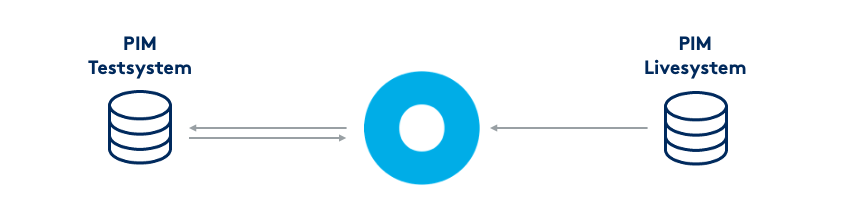
Sobald dieser Prozess abgeschlossen ist und die Produktdaten entsprechend auf das Modell hin gemappt wurden ist schnell ersichtlich, ob noch Anpassungen im Produktdatenmodell notwendig sind. Nach allfälligen Anpassungen werden die Produktdaten erneut auf die verbesserte Produktdatenmodellstruktur gemappt. Selbstverständlich werden die Produktdaten laufend aus dem Live-System exportiert. Dieser Vorgang wiederholt sich so lange bis die Produktdaten in der neuen Struktur richtig aussehen, sprich korrekt dargestellt sind.
Vorteile von Continuous Migration über die Onedot Produktdatenplattform
Der Feinschliff eines Produktdatenmodells geht nur an und mit den Produktdaten. Je schneller man das Produktdatenmodell an den vorhanden Produktdaten testen kann, desto reibungsloser ist die Einführung eines neuen PIM-Systems beziehungsweise Produktdatenmodells. Dank dem Einsatz der Produktdatenplattform von Onedot ergeben sich aber noch weitere Vorteile.
Dank der KI-gestützten Produktdaten Plattform von Onedot müssen Unternehmen weniger Personalresourcen einsetzen und benötigen für die Migration nicht die eigene IT einspannen, da Category oder Product Manager diese begleiten können. Zudem ist die KI nach Abschluss der Continuous Migration bereits auf das unternehmenseigene Produktdatenmodell hin trainiert. Dies ermöglicht nachfolgend ein sehr schnelles Hochfahren von automatisierten Lieferanten-Onboarding.
Unternehmen können so die gewünschte Produktdatenqualität über ein breites und tiefes Produktsortiment hinweg gewährleisten. Es braucht ebendiesen Ansatz 2.0 um schnell, agil und nachhaltig Anpassungen am Produktdatenmodell durchzuführen. Denn nur so kann man ein konsistentes Produktdatenmodell einführen, welches auch zukunftssicher ist.