
Blog
January 3, 2023
With the Natural Language Generation (NLG) software process, which generates natural language, content can be created automatically in a practical way. This allows a large number of products or services to be comprehensively and individually described in a short period of time. However, in order for these product descriptions to be created in a targeted and accurate manner, sufficient structured and high-quality product data must be available. This data forms the basis of automation in order to achieve high text quality.
But even without supposedly perfect product data, it is worth taking a closer look at the topic of content automation, as in many cases, source data can still be used for automation using various techniques. If a PIM system is already in use, the foundations for an optimal data structure have already been laid. But here, too, it has been shown time and again that a PIM system is not a mandatory prerequisite for automated text generation.
Requirements for data and text quality
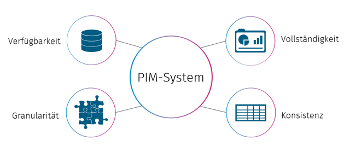
There are four basic requirements for producing high-quality content from the available data using NLG:
- Completeness. Of course, not all product information is relevant, but the attributes used in the text should be complete. It is crucial to fill in as many attribute values as possible to ensure information density and text quality.
- Availability. At first glance, the choice of data source does not appear to have any influence on data quality itself, but it should be determined in advance to ensure data availability. It has been shown on numerous occasions that the product data required for automation sometimes originates from different source systems and must first be aggregated before the data can be processed. For a fully automated workflow, a PIM system that is directly connected to the corresponding text engine is ideal..
- Granularity. It is also worthwhile ensuring that product data is as granular as possible. This allows the text to be tailored more individually to the attributes and be less generic. This enables prospective buyers to obtain the best possible information about the specific product, its features, and advantages. Granular data is also an advantage for improving product searches, leading to a higher conversion rate..
- Consistency. Finally, a certain consistency in product data is important. For example, special characters and different spellings as well as word types that have to be addressed individually in the implementation of text automation should be avoided. The corrections required as a result increase the complexity of the implementation and make it necessary to carefully check the texts as soon as new products with inconsistent attribute values are added. However, incorrect or inconsistent values can be quickly identified and corrected in the product data..
If these factors are present, the conditions for automated text generation are ideal. However, the reality is not always so ideal. Does this mean that NLG should not be used in this case?
Tips and tricks for content automation
Even if the data situation does not appear ideal at first glance, efficient workarounds can be created for this. Fallbacks, for example, are key in the event of data failures. If a specific attribute for a product is not filled in, the record designated for this can either be skipped or—in order not to lose text length—replaced by a generically formulated variant in which the attribute is not used. Alternatively, it can also be checked whether another variable is suitable as a replacement. If the existing attributes need to be described in more detail or if there are generally too few USPs to be extracted from the data, a benefit search for products, attributes, characteristics, or clusters is used.
Even with heterogeneously maintained data, manipulations can be used to remedy the situation by modifying individual cases so that they can be integrated into the text flow. However, it is important to avoid sources of error here: If new products are added after implementation is complete and these have inconsistently maintained characteristics that are not covered by the previous manipulations, these will not be caught. This characteristic must then be maintained in the engine in order to achieve good text quality.
Getting the most out of product data and NLG
Well-maintained data is essential for automatically generated texts with high informative value and quality. The criteria described—completeness, availability, granularity, and consistency—serve as guidelines for assessing data quality and individually automated text generation. The use of a PIM system is recommended for ensuring the appropriate data structure and an efficient automation process.
However, it is also true that ideal conditions are not always guaranteed, which NLG can also respond to. With the help of fallbacks and manipulations, isolated data failures and inconsistent data can be intercepted. This ensures a good reading flow and helpful product descriptions with added value for your customers. It goes without saying that this development has a positive effect on the conversion rate. After all, only satisfied customers lead to more sales.
How we can help you
Creating value-added content for your customers from product data requires a range of skills and expertise. We would be happy to advise you together with our solution partner hmmh AG. hmmh supports you with proven experts who have the technical know-how in dealing with automation platforms and PIM systems. This is the only way to ensure that the quality of the texts will convince your target group. We look forward to hearing from you.